Post
High Performance Computing Notes
HPC learning notes, MPI etc. etc. updating
This notes and learnings are collected during Georgia Tech's CSE6220 HPC Class (Professor Umit Catalyurek). The documented masterial below is my notes taken during the class, in combination with my class projects notes. The collection is for my self learning documentation purpose only.
Table of Contents
- Intro- Installation
- Chapter 01 Sum
- Chapter 02 Prefix Sum
- Chapter 03 MPI Collective
- Chapter 04 MPI Reduction
- Chapter 05 MPI Datatype
- Chapter 06 Communication Primitives
- Chapter 07 Bitonic Sort
- Chapter 08 Sample Sort
- Chapter 09 Embeddings
- Additional Resources
Install MPICH on local machines:
For my ubuntu and mac:
- Install MPICH from the tar ball: mpich-3.3.2
$ wget http://www.mpich.org/static/downloads/3.3.2/mpich-3.3.2.tar.gz
$ tar -xzf mpich-3.3.2.tar.gz
$ cd mpich-3.3.2
- Configure, avoid building fortran library as not needed:
$ ./configure --disable-fortran
... Wait until the command logs showing Configuration completed.
3. Make and install:
$ make; sudo make install
- test with
$ mpiexec --version, if make is successful, call this command, will have the following:
HYDRA build details:
Version: 3.3.2
Release Date: Tue Nov 12 21:23:16 CST 2019
CC: gcc
CXX: g++
F77:
F90:
Configure options: '--disable-option-checking' '--prefix=NONE' '--disable-fortran' '--cache-file=/dev/null' '--srcdir=.' 'CC=gcc' 'CFLAGS= -O2' 'LDFLAGS=' 'LIBS=' 'CPPFLAGS= -I/home/muyangguo/mpich-3.3.2/src/mpl/include -I/home/muyangguo/mpich-3.3.2/src/mpl/include -I/home/muyangguo/mpich-3.3.2/src/openpa/src -I/home/muyangguo/mpich-3.3.2/src/openpa/src -D_REENTRANT -I/home/muyangguo/mpich-3.3.2/src/mpi/romio/include' 'MPLLIBNAME=mpl'
Process Manager: pmi
Launchers available: ssh rsh fork slurm ll lsf sge manual persist
Topology libraries available: hwloc
Resource management kernels available: user slurm ll lsf sge pbs cobalt
Checkpointing libraries available:
Demux engines available: poll select
The cluster used MPI lib is mvapich2, I chose to use MPICH on my local machine, as many features for clusters and networks are not needed. Alternatively, another open source distribution is OpenMPI. I just go with MPICH, either one should work.
01. A Sum algorithm to start:
This is a programming assignment from my 6220 class, to perform a sum with MPI.
The code is archived here
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define MPI_CHK(err) if (err != MPI_SUCCESS) return err
double local_sum(long int local_n,long int local_c,double local_nums[],double* p);
int main(int argc, char *argv[]) {
if(argc!=3){
fprintf(stderr,"argc invalid, must have N, C specified. aborting the program ... \n");
exit(EXIT_FAILURE);
}
int rank,size;
// Initialize the MPI environment
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int p = size;
int err;
const int root = 0;
long int arg_buff[2];
if (rank == root){
arg_buff[0]= atoi(argv[1]);
arg_buff[1] = atoi(argv[2]);
}
// all ranks start calling MPI_Bcast, root to all other ranks, assign a buff to send the argv, buff = [n,c], already converted to int type
MPI_Bcast(&arg_buff, 2, MPI_DOUBLE, root, MPI_COMM_WORLD);
//start the timer
double t_start = MPI_Wtime();
//after Bcast, cast values to variable n, c , and calculate each rank's new seed number
long int n;
long int c;
n = arg_buff[0];
c = arg_buff[1];
long int local_c;
local_c = c+rank;
// printf("[%d]: After Bcast, number size is %li, new seed number is %li\n",rank, n, local_c);
int d = log2(p);
//printf("[%d]: is having %d dimensions \n",rank,d);
// consider the N/P, N is not divisible by P cases, we need to assign the maximum numbers for a rank, so some may have one more number than the other.
int local_n;
int remainder = n%size;
if (remainder != 0 && remainder >= rank+1){
local_n = n/size + 1;
//printf("[%d]: assigned %d size numbers to this processor\n",rank, local_n);
}
else{
local_n = n/size;
//printf("[%d]: assigned %d size numbers to this processor\n",rank, local_n);
}
// after calculated the local_c, the seed for each processor, and the local_n, the number size //assigned to each processor.
// we need to generate the random numbers based on the local_c, local_n;
//specify the request array size, based on local_n assigned to each processor
double local_nums[local_n+1];
//malloc the memory needed
double* ptr = (double *) malloc ( sizeof(double) * local_n );
if (ptr == NULL){
printf("[%d]: Error! memory not allocated.\n",rank);
exit(EXIT_FAILURE);
}
double local_s = local_sum(local_n,local_c,local_nums,ptr);
free(ptr);
ptr = NULL;
//start send local sum in pairs
for( int j= 0; j < d; j++ ){
int bit = pow(2, j);
if ((rank & bit) !=0){
// printf("j = %d with rank %d, send to %d\n",j,rank,(rank ^ bit));
MPI_Send(&local_s, 1, MPI_DOUBLE,(rank ^ bit), 111, MPI_COMM_WORLD);
MPI_Finalize();
return 0;
}
else{
MPI_Status stat;
double local_s_received;
MPI_Recv (&local_s_received, 1, MPI_DOUBLE, (rank ^ bit), 111, MPI_COMM_WORLD, &stat);
local_s = local_s+local_s_received;
}
}
if (rank==0){
double sum = local_s;
double t_end = MPI_Wtime();
double t_running = t_end - t_start;
printf("sum is: %f",sum);
FILE *f = fopen("output.txt", "a+");
if (f == NULL)
{
printf("Error opening file!\n");
exit(EXIT_FAILURE);
}
fprintf(f, "N= %ld, P = %d, C= %ld, S= %f\nTime= %f\n", n,p,c,sum,t_running);
fclose(f);
}
// Finalize the MPI environment.
MPI_Finalize();
return 0;
}
double local_sum(long int local_n,long int local_c, double local_nums[],double* p){
double local_s;
srand48(local_c);
int i;
p = local_nums;
for (i=0; i<local_n; i++){
local_nums[i] = drand48();
// printf(" generating:%f \n",local_nums[i]);
local_s = local_s + local_nums[i];
}
return local_s;
}
mpicxx ./prog1.cpp -o prog1
mpirun -np 8 ./prog1 500 1
The algorithm is simple but very informative:
Algorithm (for P_i)
sum = add local N / P numbers
for j = 0 to d-1 {
if ((rank AND 2^j)!= 0) {
send sum to (rank XOR 2^j);
exit;
}
else {
receive sum' from (rank XOR 2^j);
sum = sum + sum';
}
}
if (rank == 0)
And here we use dimension d to determine which pairs of processors communicate with each other. And we use bitwise operator to XOR and AND to find the pairs for iterations. We could do that because the the sum should have log(P) iterations and we considered p is a power of 2.
some learning notes to pay attention for this example
- MPI_Bcast is a MPI step all processors need to perform.
- For long int, we should use MPI_DOUBLE
- Since it is log(P) iterations and sum goes to one last processor(root), we should exit the MPI for processors done their jobs during the iterations and won't need to communicate with others , by using MPI_Finalize() and return to exit the process.
- for N sizes not dividable for P, we could allocate n and n+1 sizes by calculating the mod and compare to the rank nums.
02. Parallel Prefix Sum:
Input: n numbers:
Output:
Math:
Parallel Prefix Sum Alg-1
Algorithm-1 (for Pi), suppose for n number, we have p=n processors
total_sum←prefix_sum←local_number
for j=0 to d-1 do
rank’ ←rank XOR 2^j
send total_sum to rank’
receive received_sum from rank’
total_sum←total_sum+ received_sum
if (rank > rank’)
prefix_sum←prefix_sum+ received_sum
endfor
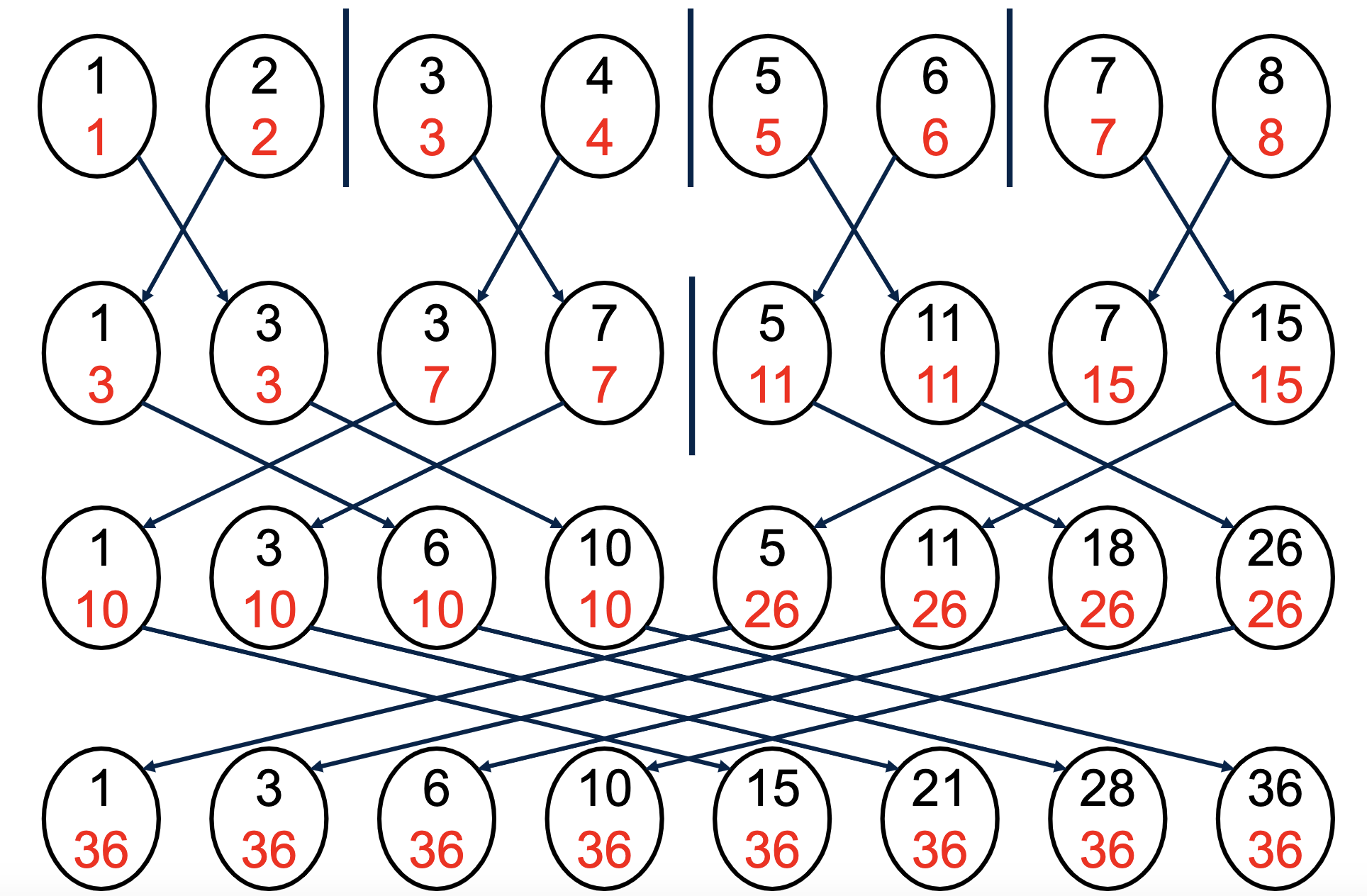 here black color denote prefix sum, read denote total sum
here black color denote prefix sum, read denote total sum
However, if n>p_new, we have to use Brent's Lemma, to let each p_new_i simulate p/p_new_i's processors.
So each p_new_i will have to assign a chunk of n numbers locally and perform the Alg-1.
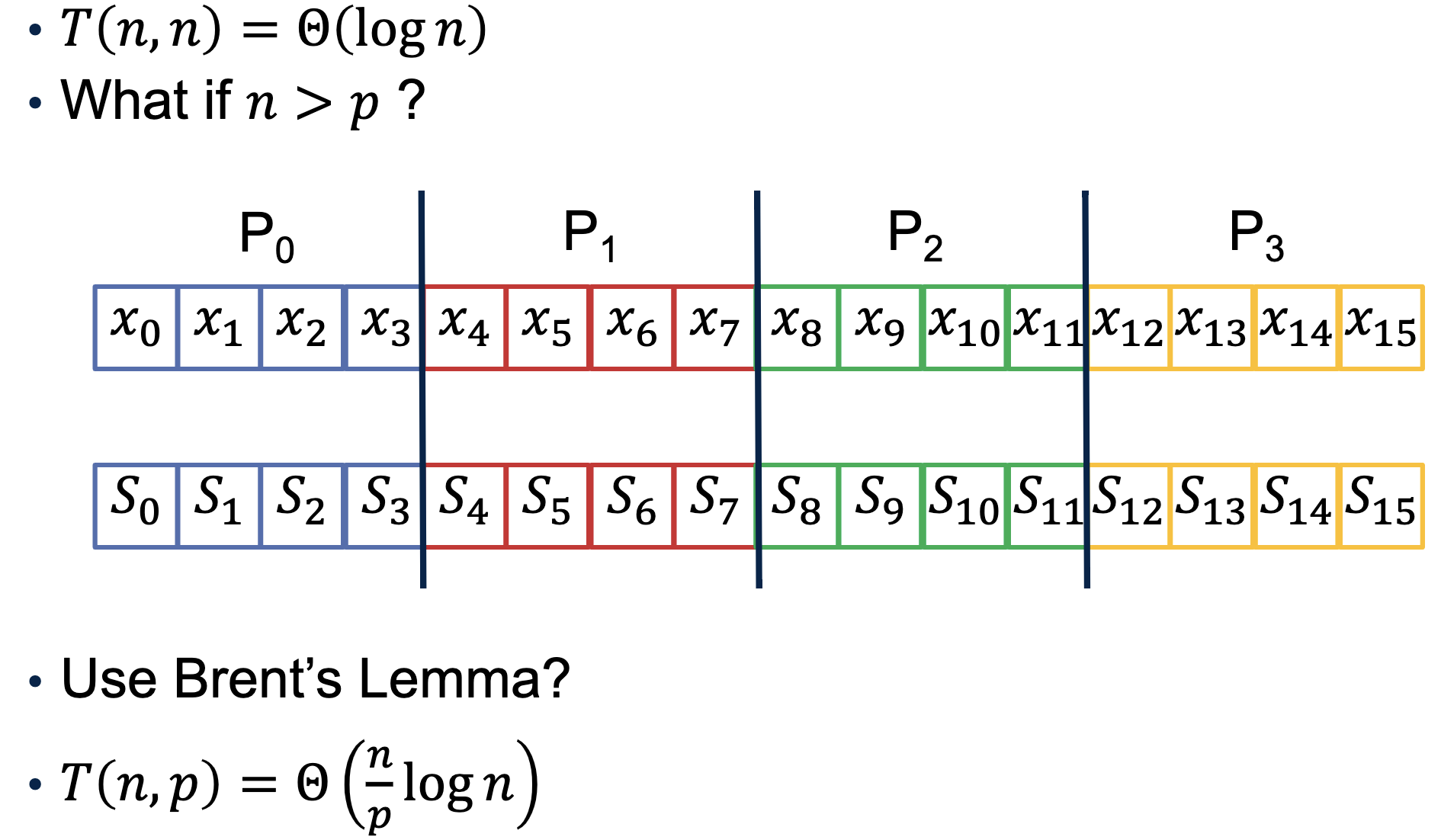
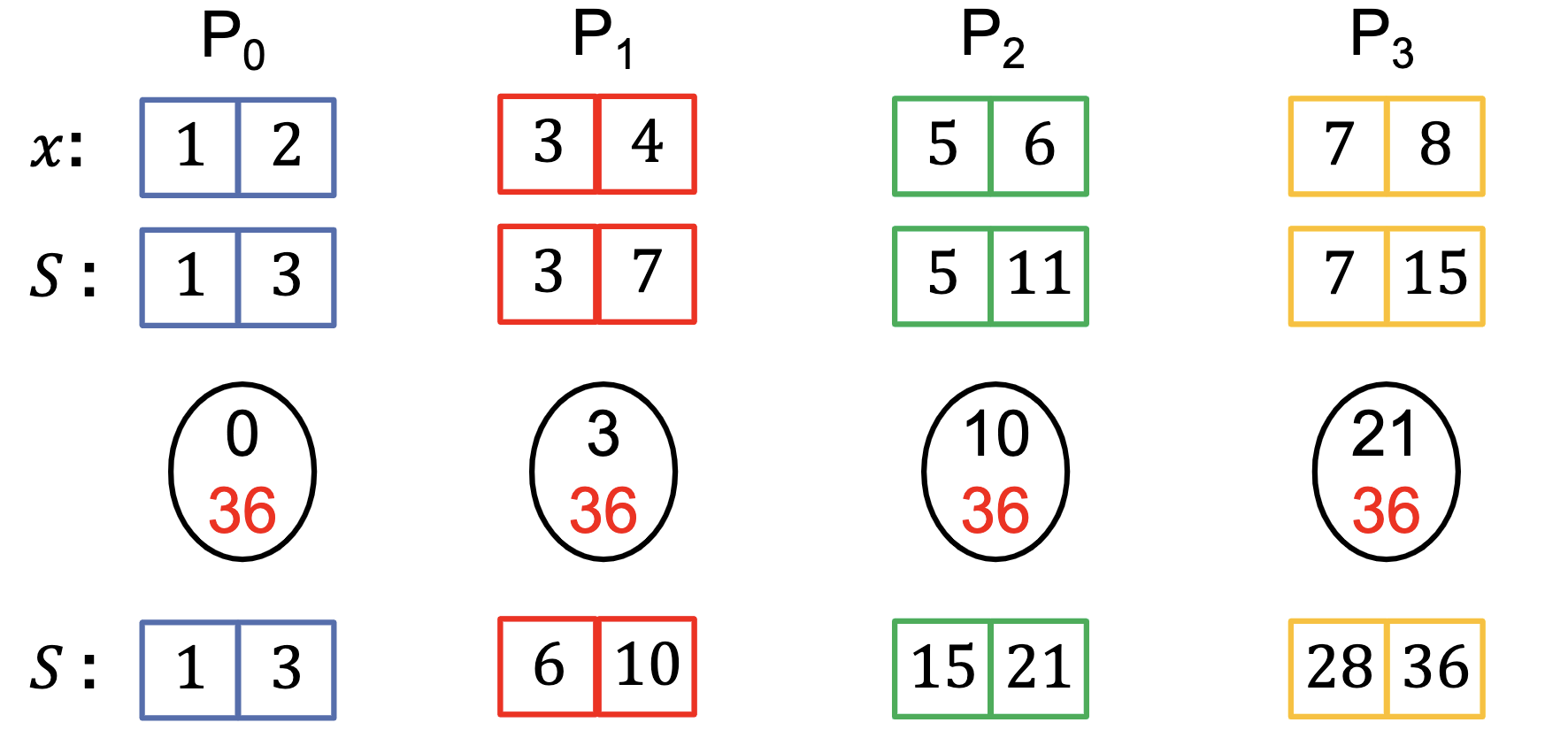
Parallel Prefix Sum Alg-2
1.Compute prefix sum locally on each processor
2.Perform parallel prefix sum (Alg-1)*[1] using the last local prefix sum on each processor
3.Add the result of parallel prefix sum on a processor to each of its local prefix sum
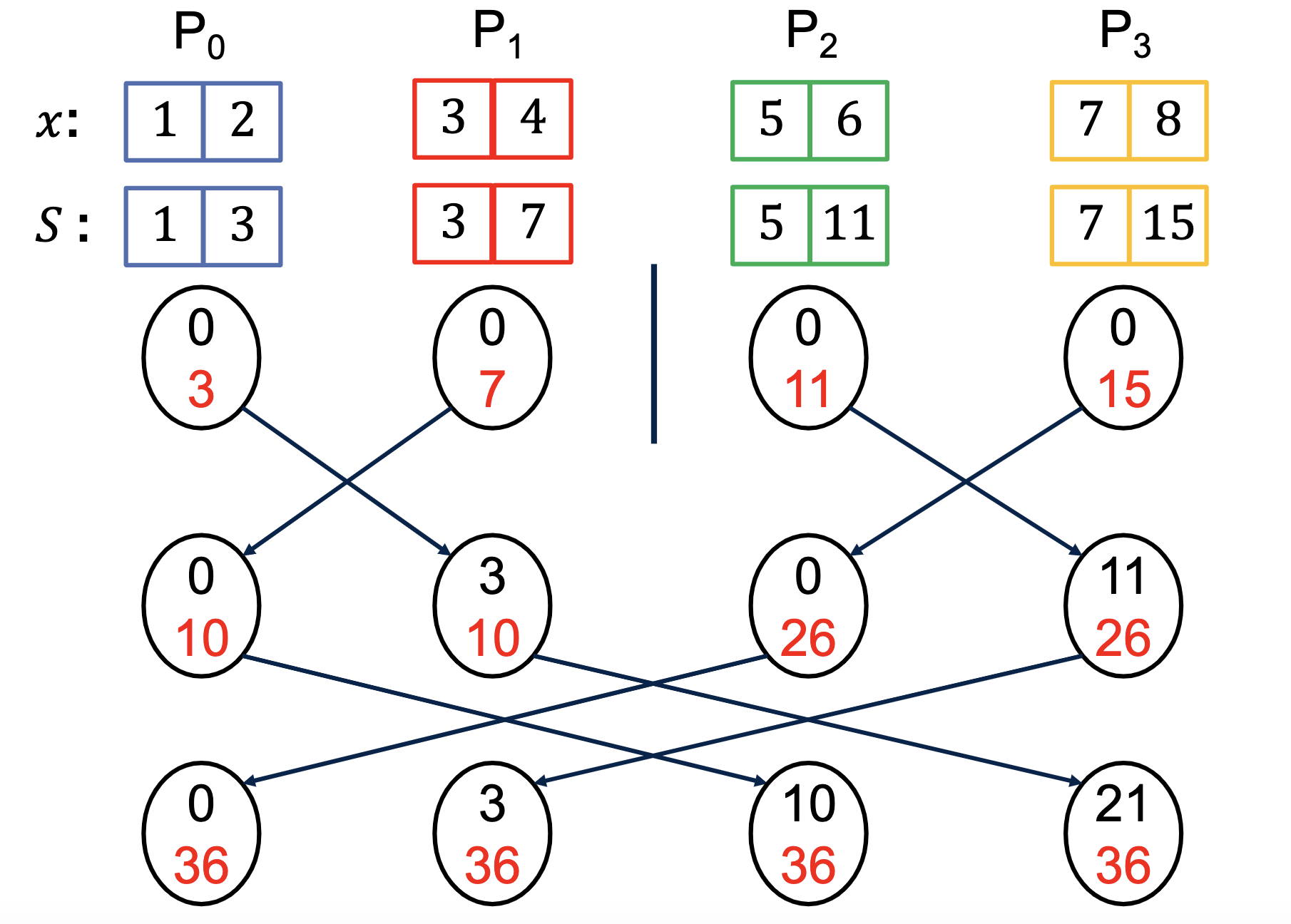 here black color denote prefix sum, read denote total sum
here black color denote prefix sum, read denote total sum
*[1] We need to Modify Alg-2 to start with prefix_sum←0
Note:
- What if n is not divisible by p?
Assign max to each processor: some processors will have 1 more element than the others. - What if p is not a power of 2?
Find p'= a power of 2 such that p'/2 < p < p'. Run the code like you have p' processors.Ignore communications to/from non-existing processors, i.e., rank >= p.
03 MPI Study - Collective Primitives
Collective Communication:
- All processes within a comminicator must participate
- All collective operations are blocking
- Except for MPI_Barrier, No synchronization can be assumed.
- All collective opertations are guaranteed to not interfere with point-to-point message.
- Collective operations can be impletemented using only point-to-point calss.
- In practice, they are optimized to use various hardware (interconnected) properties.
Barrier:
- Block until all processes called the barrier:
int MPI_Barrier(MPI_Commcomm);- Establish full synchronization
Measuring time:
#include <mpi.h>
#include <iostream>
intmain(intargc, char*argv[]) {
MPI_Init(&argc, &argv);
doublet0 =MPI_Wtime();// ...
MPI_Barrier(MPI_COMM_WORLD);
doublet1 =MPI_Wtime();
std::cout<<(t1 -t0) <<std::endl;returnMPI_Finalize();
}MPI provides a function to check execution time:
double MPI_Wtime();Broadcast:
Broadcast a message from one process (root) to all other processes:
int MPI_Bcast(void* buf, int count, MPI_Datatype type,int root, MPI_Comm comm);Example:
#include <mpi.h>
#include <iostream>
int main(intargc,char*argv[]){
int rank;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
double x =0.0;
if(rank ==0) x =-13.13;
MPI_Bcast(&x,1,MPI_DOUBLE,0,MPI_COMM_WORLD);
std::cout<<x <<std::endl;
returnMPI_Finalize();
}Gather:
Gather data from all processes to one process(root). Like each friend bring a dish to the host's home.
int MPI_Gather(void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm); Example:
#include <mpi.h>
#include <iostream>
#include <vector >
int main(intargc,char*argv[]){
int rank,size;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
std::vector<int>buf;
if(rank ==0) buf.resize(size,-1);
MPI_Gather(&rank ,1,MPI_INT,&buf[0],1,MPI_INT,0,MPI_COMM_WORLD);
if(rank ==0) std::cout<<buf.back()<<std::endl;
returnMPI_Finalize();
}Scatter:
Scatter data from one process to all processes:
int MPI_Scatter(void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm); Example:
int main(intargc,char*argv[]){
int rank,size;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
float x =13;
std::vector<float>buf;
if(rank ==0){buf.resize(size,-1);
for(inti =0;i <size;++i) buf[i]=1.0/(1+i);
}
MPI_Scatter(&buf[0],1,MPI_FLOAT,&x,1,MPI_FLOAT,0,MPI_COMM_WORLD);
std::cout<<rank <<" "<<x <<std::endl;
returnMPI_Finalize();
}Scatterv
int MPI_Scatterv(void* sbuf, int *scounts, int *displs,MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm); Example:
#include <mpi.h> #include <stdio.h> #include <stdlib.h> #include <math.h> #define N 4 int main(intargc, char *argv[]){ int rank, size;// this process' rank, and the number of processes int *sendcounts; // number of elements to send to each process int *displs;// displacements where each segment begins int sum=0;// Sum of counts. Used to calculate displacements char rec_buf[100];// buffer where the received data should be stored char data[N][N]={// the data to be distributed{'a','b','c','d'}, {'e','f','g','h'},{'i','j','k','l'}, {'m','n','o','p'} }; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); MPI_Comm_size(MPI_COMM_WORLD,&size);
sendcounts= (int*) malloc(sizeof(int)*size);
displs= (int*) malloc(sizeof(int)*size);
// calculate send counts and displacements
int rem = (N*N) % size;// elements remaining after division among processes
for (inti=0; i<size; i++) {
sendcounts[i] = (N*N) / size;
if (rem--> 0)
sendcounts[i]++;
displs[i] = sum;
sum += sendcounts[i];
}// print calculated send counts and displacements for each process
if (0 == rank) {
for (inti=0; i<size; i++)
printf("sendcounts[%d] = %d\tdispls[%d] = %d\n", i, sendcounts[i],i, displs[i]);
}// divide the data among processes as described by sendcounts and displs
MPI_Scatterv(&data, sendcounts, displs, MPI_CHAR,&rec_buf, 100, MPI_CHAR, 0, MPI_COMM_WORLD);
printf("%d: ", rank);
for (inti=0; I < sendcounts[rank]; i++) {
printf("%c\t", rec_buf[i]);
}
printf("\n");
MPI_Finalize();
free(sendcounts);
free(displs);
return 0;
}
</div>
Run:
% mpirun-np 3 scatterv sendcounts[0] = 6 displs[0] = 0 sendcounts[1] = 5 displs[1] = 6 sendcounts[2] = 5 displs[2] = 11 0: a b c d e f 1: g h i j k 2: l m n o p
### Allgather:
Allgather: Corresponds to each process broadcasting its data.
```c++
int MPI_Allgather(void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm);
Example:
int main(intargc,char*argv[]){
int rank,size;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
std::vector<int>buf;buf.resize(size,-1);
MPI_Allgather(&rank,1,MPI_INT,&buf[0],1,MPI_INT,MPI_COMM_WORLD);returnMPI_Finalize();
}AlltoAll
Alltoall: every process has one message for every other process
int MPI_Alltoall(void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm); Example:
int main(intargc,char*argv[]){
int rank,size;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
std::vector<float>send(size);
std::vector<float>recv(size,-1);
for(inti =0;i <size;++i) send[i]=rank;
MPI_Alltoall(&send[0],1,MPI_FLOAT,&recv[0],1,MPI_FLOAT,MPI_COMM_WORLD);
returnMPI_Finalize();
}04 MPI Study - Reduction Primitives
MPI Reduce
int MPI_Reduce(void* sbuf, void* rbuf, int count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm); Example:
// assume each processor has one element:
int a =A[rank];
int sum =0;
MPI_Reduce(&a,&sum,1,MPI_INT,MPI_SUM ,0,MPI_COMM_WORLD);
std::cout<<sum <<std::endl;MPI Allreduce:
MPI_Allreduce= MPI_Reduce+ MPI_Bcast
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count,MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)Example:
while(true){
// compute ...
// check termination
int terminate =...;
int result;
MPI_Allreduce(&terminate,&result,1,MPI_INT,MPI_LAND,MPI_COMM_WORLD);
if(result ==1) break;
}05 MPI Study - MPI Datatypes
[ Updating]
06 Communication Primitives (Important)
[ Updating ]
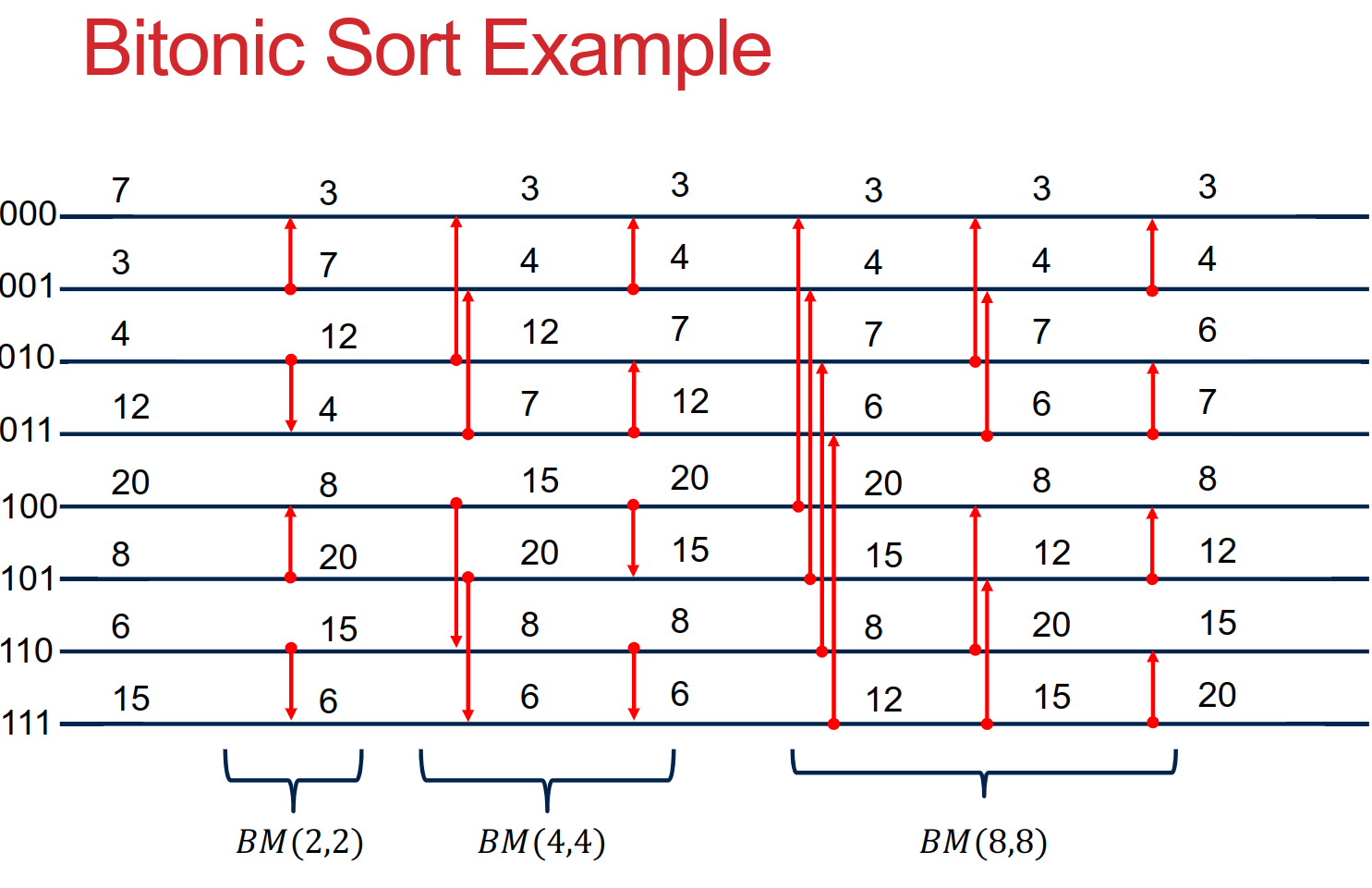
07 Bitonic Sort
Bitonic Sort Alg A sequence is called Bitonic if it is first increasing, then decreasing.
- Bitonic sort does O(n Log 2n) comparisons.
- The number of comparisons done by Bitonic sort are more than popular sorting algorithms like Merge Sort [ does O(nLogn) comparisons], but Bitonice sort is better for parallel implementation because we always compare elements in predefined sequence and the sequence of comparison doesn’t depend on data. Therefore it is suitable for implementation in hardware and parallel processor array.
Bitonic Sequence (three types)
Bitonic sequence: is bitonic if any k such that: (one of the three following types)
- is non-decreasing and is non-increasing
- is non-increasing, and is non-decreasing
- There is a cyclical shift of the sequence that makes (a) or (b) true.
Bitonic Split:
A bitsonic sequence l satsfied the above types can be decomposed into , sub sequences. This is called the bitonic split.
Bitonic Lemma:
Let be a bitonic sequence, and and result from its bitonic split, then the following results are met:
- and are also bitonic.
- And
Sub-Lemma
Cyclical shift does not change the bitonicnature of the sequence nor the min (or max) element in the sequence!
Let be a bitonicsequence and be a cyclical shift.
- Bitonic split l into and ,
- Bitonic split l' into and
- Then is a cyclical shift of , is a cyclical shift of
Proof:
Let ,
And ,
Bitnoic Merge:
Turning a bitonic sequence into a sorted sequence using repeated bitnoic split operations.
BM(p,p) = O(log p)
Bitonic Sort:
- BS(p,p) = BM(2,2) + BM(4,4) + ... + BM(p,p)
- BS(p,p) = 1+2+3+...+ logP
- BS(p,p) = O(log^2 p)
Bitonic Sort Alg:
for i=0 to (log p)-1 do
for j=i downto 0 do
if (i+1)st bit is 0 then
Compare_Exchange↑ with (Rank XOR 2j)
else
CompareExchange↓ with (Rank XOR 2j)
endfor
endfor
Bitonic Sort Complexity:
- T(p,p) =
- Computation time :
- Communication time :
What if n>p?
- sort n/p local elements
- Run bitonic sort with CompareExchange replaced by MergeSplit
- Computation time:
- Communication time:
08 Sample Sort
Sample sort:
- sort locally
- Find p-1 "good" splitters
- Split local sequence into p segments according to splitters
- Many-to-many communication
Good splitters:
- Each processor should receive at most elements in 4.
- Finding splitters should not be too expensive (complexity)
Finding "good" Splitters by regular sampling:
- pick p-1 equally spaced elements from the local sorted array on each processor (called local splitters from here onwards)
- Sort all p(p-1) local splitters using bitonic sort
- Pick p-1 global splitters: From the sorted local splitter array, pick last local splotter on each processor (excl. last processor)
- ALLGATHER global splitters
Theorem:
Each processor receives at most elements.
Sample sort proof:
09 Embedding:
Source & Target
- Algorithm designed for source network.The system you have is Target network.
- Source and Target can be modeled as graphs.
- Interested in the case where Target network can support(relaxed) hypercubic permutations.
Performance Metrics
Embedding a source graph G(V,E) into a target graph G'(V',E'):
- Congestion : Maximum number of edges from E that are mapped onto a single edge in E'
- Dilation: Maximum number of edges in E’that any edge in Eis mapped to.
- Load: Maximum number of nodes in Vthat map to a single node in V’
- Expansion: The ratio of the number of nodes V’to that in V.
Computation slows down by a factor of Load.
Communication slows down by a factor of Congestion X Dilation.
Expansion > 1 indicates waste of resources.
Mapping: Load = Congestion = Dilation = 1
Key Ideas:
When embedding from sources to target is a mapping:
- Mapping only needs to specify node mapping. Edge mapping is implied.
- Parallel run-time on the target topology is the same as that on the source topology.
- Efficiency is preserved when execution of the algorithm is shifted from source topology to target topology!
- It is possible there can be a different parallel algorithm with better efficiency directly designed for the target topology.
- This concern is eliminated if the parallel algorithm designed for the source topology is optimally efficient.
Linear Arrays
Additional Resources
Copyright 2019 Muyang Guo, all rights reserved. Redistribution of the work must cite the original source.