Post
Practice Notes 1 — String
Chapter 1 经典String题目
-
LeetCode 409 Longest Palindrome
Problem:
Given a string which consists of lowercase or uppercase letters, find the length of the longest palindromes that can be built with those letters.
This is case sensitive, for example "Aa" is not considered a palindrome here.
Notes:
Assume the length of given string will not exceed 1,010.
Example:
Input: "abccccdd" Output: 7 Explanation: One longest palindrome that can be built is "dccaccd", whose length is 7.Solution: 哈希表
class Solution: def longestPalindrome(self, s: str) -> int: ### Hash Set Hash = set() res = 0 for char in s: if char not in Hash: Hash.add(char) else: Hash.remove(char) res += 2 if Hash: res += 1 return res
-
LeetCode 5 Longest Palindromic Substring
Problem:
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
Example 1:
Input: "babad" Output: "bab" Note: "aba" is also a valid answer.Example 2:
Input: "cbbd" Output: "bb"Solution 1: 中心线枚举法 + 背向双指针
class Solution: def longestPalindrome(self, s: str) -> str: if not s: return s # 利用tuple来建立(长度,起点)的二元组方便作MAX操作。 length_start = (0, 0) # 枚举中心线,分情况讨论,odd类型 “...bab...", even类型 "...bb..." for mid in range(len(s)): # odd type : left = right = mid length_start = max(length_start, self.findPalindrome(s, mid, mid)) # even type: left = mid, right = mid + 1 length_start = max(length_start, self.findPalindrome(s, mid, mid + 1)) return s[length_start[1]:length_start[0] + length_start[1]] def findPalindrome(self, s, left, right): while left >= 0 and right < len(s) and s[left] == s[right]: left -= 1 right += 1 return right-left-1, left+1Solution 2: 区间型DP (倒序遍历,速度很慢,会超时需要优化,区间型不适合这么写)
class Solution: """ @param s: input string @return: a string as the longest palindromic substring """ def longestPalindrome(self, s): # write your code here if not s: return s # 区间型DP f = [[False] * len(s) for _ in range(len(s))] res = (1, 0) # (length, start) for i in range(len(s) - 1, -1, -1): for j in range(len(s)): # initialization # pruning if i > j: continue # initialization #single if i == j: f[i][j] = True continue # initialization #double if j == i + 1 and s[i] == s[j]: f[i][j] = True res = max(res, (2, i)) continue if i + 1 <= len(s) - 1 and j >= 1 and j > i + 1: f[i][j] = f[i + 1][j - 1] and s[i] == s[j] if f[i][j]: res = max(res, (j - i + 1, i)) return s[res[1]:(res[0] + res[1])]Solution 3:
时间复杂度不变但更精简版的区间型DP (按长度递推,已知现在长度为1推长度为2 ... 对每个已知长度,遍历要求的下一个长度的i,j)
class Solution: def longestPalindrome(self, s: str) -> str: if not s: return s n = len(s) # 区间型DP f = [[False] * n for _ in range(n)] ### 初始化长度为1的都是True for i in range(n): f[i][i] = True ### 对于长度为2如此初始化的原因是根据f[i][j] = s[i] == s[j] and f[i + 1][j - 1] ### 当求length = 2 的情况时,f[0][1] = s[0] == s[1] and f[1][0] ### 出现i比j大的情况,所以要提前初始化,f[i][i - 1] = True,才能让s[i] s[i-1]起决定性的比较。 for i in range(1, n): f[i][i - 1] = True longest, start, end = 1, 0, 0 ### length 可以从1到 n-1, 这里的length是指:假设given length=1, 求出下一个length的情况,所以是从1到n-1,用 n-1求出n。 for length in range(1, n): ### 那么i应该是 0,1,2,... , n - length - 1 ### 比如在已知 length = 2 时, 要求的长度为3的i最后一位应该在 n - 2 - 1, j 为 n - 1 for i in range(n - length): ### 根据 length 和枚举 i算出当前的j j = i + length f[i][j] = s[i] == s[j] and f[i + 1][j - 1] if f[i][j] and length + 1 > longest: longest = length + 1 start, end = i, j return s[start:end + 1]
-
LeetCode 647 Palindromic Substrings
Problem:
Given a string, your task is to count how many palindromic substrings in this string.
The substrings with different start indexes or end indexes are counted as different substrings even they consist of same characters.
Example:
Input: "abc" Output: 3 Explanation: Three palindromic strings: "a", "b", "c". Input: "aaa" Output: 6 Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".Notes:
The input string length won't exceed 1000.
Solution 1: 区间型DP(与上题相似)
class Solution: def countSubstrings(self, s: str) -> int: if not s: return 0 n = len(s) f = [[False] * n for _ in range(n)] ### 区间型DP for i in range(n): f[i][i] = True for i in range(1, n): f[i][i - 1] = True res = n for length in range(1, n): for i in range(n - length): j = i + length f[i][j] = s[i] == s[j] and f[i + 1][j - 1] if f[i][j]: res += 1 return resSolution 2: 区间型DP(更简洁的写法)
class Solution: def countSubstrings(self, s: str) -> int: if not s: return 0 n = len(s) dp = [[0] * n for _ in range(n)] ans = 0 for j in range(n): for i in range(j + 1): if(s[i] == s[j] and (j - i <= 2 or dp[i + 1][j - 1] == 1)): dp[i][j] = 1 ans += dp[i][j] return ans
-
LeetCode 214 Shortest Palindrome
Problem:
Given a string s, you are allowed to convert it to a palindrome by adding characters in front of it. Find and return the shortest palindrome you can find by performing this transformation.
Example:
Input: "aacecaaa" Output: "aaacecaaa" Input: "abcd" Output: "dcbabcd"Solution 1: O(N^2) Brute Force
从后往前每次减去一个字符后子串是否为回文串。 答案为将减去的部分翻转后接入最前面。
class Solution: """ @param str: String @return: String """ def shortestPalindrome(self, s: str) -> str: if not s: return s n = len(s) for i in range(n - 1, -1, -1): substr = s[:i + 1] if self.isPalindrome(substr): if i == n - 1: return s else: return (s[i + 1:] [::-1]) + s[:] def isPalindrome(self, str): left, right = 0, len(str) - 1 while left < right: if str[left] != str[right]: return False left += 1 right -= 1 return TrueSolution 2: O(N) Rabin-Karp Rolling Hash
参考下 LeetCode 28 implement strStr() 这道题:
因为这题要找出从左侧起的最长palindrome, 所以target的长度是变化的(此处和strStr那题不太一样)。 这里我们比较 source = s[0 : i + 1], target = source[: : -1] 两个的Hash值是否相同。
举个例子:
‘aaccbc’
我们要找到‘aacc’ 那么我们找到‘aacc'之前要比较的是
source: a ; target: a (符合条件)
source: aa ; target: aa (符合条件)
source: aac ; target: aac (不符合条件)
source: aacc ; target: aacc (符合条件)
... ...
直到遍历完整个str,最后一个符合条件的则是以0 index开头的最长palindromic substring。
可以看出每次求target的hash值, 实际上是求source reverse的哈希值,所以要用POWER的迭代来计算。这里注意POWER在长度为1,(index为0)时,应该为1。(这里举个例子比较方便推算,比如上面的例子,计算’aab’ source_hash = a x 31^2 + a x 31^1 + b x 31 ^0 属于正序求Hash的方法,迭代关系应该是: source_hash = ( source_hash * BASE + ord(s[i]) ) % MOD 。
相应的‘aab’的reverse ‘baa’ 更新到‘b’这个字母,所以应该是 target_hash = b x 31^2 + a x 31^1 + a x 31^0, 可以看出每次迭代到的字母的位数是上升的,所以对于target的迭代关系应该是 target_hash = ( target_hash + ord(s[i]) * POWER) % MOD 。这里的POWER也是当前迭代的POWER。
使用Rolling Hash的方法一定要在找到可能的结果时进行Collision Check。避免hash冲突造成的错误。
class Solution: """ @param str: String @return: String """ def shortestPalindrome(self, s: str) -> str: if not s: return s n = len(s) # 31 ^ m MOD = 1000000 POWER = 1 BASE = 31 source_hash = 0 target_hash = 0 end = 0 for i in range(n): if i > 0: POWER = (POWER * BASE) % MOD source_hash = ( source_hash * BASE + ord(s[i]) ) % MOD target_hash = ( target_hash + ord(s[i]) * POWER) % MOD if source_hash == target_hash: print(source_hash, target_hash) if self.collisionCheck(s[0:i + 1], s[0:i + 1][::-1]): end = i return s[end + 1:n][::-1] + s def collisionCheck(self, source, target): if source == target: return True else: return False
-
LeetCode 28 Implement strStr()
Problem:
Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example:
Input: haystack = "hello", needle = "ll" Output: 2 Input: haystack = "aaaaa", needle = "bba" Output: -1Solution 1: Brute Force O(N^2)
### 方法一: class Solution: def strStr(self, haystack: str, needle: str) -> int: if haystack == needle: return 0 n = len(needle) out = -1 for i in range(len(haystack)-n+1): if haystack[i:i+n] == needle: return i return out ### 方法二: class Solution: def strStr(self, haystack: str, needle: str) -> int: if haystack == needle: return 0 for i in range(len(haystack)-len(needle)+1): for j in range(len(needle)): if haystack[i+j] != needle[j]: break else: return i ### 此处运用了 for else 这个小技巧 处理。for 里面的 break 如果被执行了,就不会执行else了。 如果 没被执行,则会进入else。 ### 这里注意 for 和 else 是并列的。 return -1Solution 2: Rabin-Karp Rolling Hash O(N)
参考我的Blog(https://muyangguo.xyz/rabin-karp-algorithm-notes/)。
class Solution: def strStr(self, haystack: str, needle: str) -> int: ### Rabin-Karp rolling hash if not haystack and needle: return -1 if not needle: return 0 ### Initialization MOD = 1000000 POWER = 1 BASE = 31 roll_hash = 0 needle_hash = 0 for i in range(len(needle)): POWER = POWER * BASE % MOD needle_hash = ( needle_hash * BASE + ord(needle[i]) ) % MOD for i in range(len(haystack)): roll_hash = (roll_hash * BASE + ord(haystack[i]) ) % MOD if i < len(needle) - 1: continue ### abcd - a if i >= len(needle): roll_hash = (roll_hash - (ord(haystack[i-len(needle)]) * POWER) % MOD) % MOD if roll_hash < 0: ### 做循环处理 roll_hash += BASE ### double check, avoid the collision if roll_hash == needle_hash: if haystack[i - len(needle) + 1: i + 1] == needle: return i - len(needle) + 1 return -1
-
Problem:
Given a string, determine if it is a palindrome, considering only alphanumeric characters and ignoring cases.
Notes:
For the purpose of this problem, we define empty string as valid palindrome.
Example:
Input: "A man, a plan, a canal: Panama" Output: true Input: "race a car" Output: falseSolution: 相向双指针 + 跳过非法index操作,很经典的模板
class Solution: def isPalindrome(self, s: str) -> bool: left, right = 0, len(s) - 1 while left < right: ### 这里是跳过操作: while left < right and not self.isValid(s[left]): left += 1 while left < right and not self.isValid(s[right]): right -= 1 if left < right and s[left].lower() != s[right].lower(): return False left += 1 right -= 1 return True def isValid(self, char): return char.isdigit() or char.isalpha()
-
LeetCode 680 Valid Palindrome II
Problem:
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a palindrome.
Example:
Input: "aba" Output: True Input: "abca" Output: True Explanation: You could delete the character 'c'.Notes:
The string will only contain lowercase characters a-z. The maximum length of the string is 50000.
Solution: 相向双指针,利用返回left,right index的方法巧妙地解决这个问题
class Solution: def validPalindrome(self, s: str) -> bool: if not s: return False ### 先找到不一样的left和right在哪 left, right = self.find_ptrs(s, 0, len(s) - 1) ### 如果筛出来的left和right相等, ### 证明不存在不相等的字符,所以直接return True if left == right: return True else: ### 如果找到了不相等的字符的位置, ### 分清况讨论,这里用一个子函数封装了一下: return self.isPalindrome(s, left + 1, right) or self.isPalindrome(s, left, right - 1) ### 此处注意这两个子函数设计的时候, 要避免代码重复 ###,所以需要机智的利用返回指针和判断指针位置的方法。 ### 不要写成使用两次双指针代码相同,但却不把逻辑封装。 def find_ptrs(self, s, left, right): while left < right : if s[left] != s[right]: return left, right left += 1 right -= 1 return left, right def isPalindrome(self, s, left, right): res_left, res_right = self.find_ptrs(s, left, right) return res_left >= res_right
-
Problem:
Given two words word1 and word2, find the minimum number of operations required to convert word1 to word2.
You have the following 3 operations permitted on a word:
- Insert a character
- Delete a character
- Replace a character
Example:
Input: word1 = "horse", word2 = "ros" Output: 3 Explanation: horse -> rorse (replace 'h' with 'r') rorse -> rose (remove 'r') rose -> ros (remove 'e') Input: word1 = "intention", word2 = "execution" Output: 5 Explanation: intention -> inention (remove 't') inention -> enention (replace 'i' with 'e') enention -> exention (replace 'n' with 'x') exention -> exection (replace 'n' with 'c') exection -> execution (insert 'u')Solution 1: 经典的匹配型DP (未优化)
class Solution: def minDistance(self, word1: str, word2: str) -> int: m, n = len(word1), len(word2) f = [[0] * (n + 1) for _ in range(m + 1)] # convert word 1 to word 2 # word 1 前i个数变成word 2 的前j个数 需要最少的步骤 用 f[i][j] 表示 for i in range(m + 1): for j in range(n + 1): # 初始化 ### when word1 is None, insert, insert, insert ... to word1 till word1 is word2 ### after this step we need to jump to next, use continue to avoid the overwrite if i == 0: f[0][j] = j continue ### when word2 is None, delete, delete, delete ... from word1 till word1 is word2 ### after this step we need to jump to next, use continue to avoid the overwrite if j == 0: f[i][0] = i continue # 决策: if word1[i - 1] != word2[j - 1]: ### delete, insert, replace: f[i][j] = min(f[i - 1][j], f[i][j - 1],f[i - 1][j - 1]) + 1 else: ### no need to operate when equal f[i][j] = f[i - 1][j - 1] return f[m][n]Solution 2: 经典的匹配型DP (二维数组空间优化)
class Solution: def minDistance(self, word1: str, word2: str) -> int: # 二维数组优化版本 m, n = len(word1), len(word2) f = [[0] * (n + 1) for _ in range(2)] for i in range(m + 1): for j in range(n + 1): # 初始化 if i == 0: f[0][j] = j continue if j == 0: f[i % 2][0] = i continue # 决策: if word1[i - 1] != word2[j - 1]: ### delete, insert, replace: f[i % 2][j] = min(f[(i - 1) % 2][j], f[i % 2][j - 1],f[(i - 1) % 2][j - 1]) + 1 else: ### no need to operate when equal f[i % 2][j] = f[(i - 1) % 2][j - 1] return f[m % 2][n]
-
LeetCode 1216 Valid Palindrome III
Problem:
Given a string s and an integer k, find out if the given string is a K-Palindrome or not.
A string is K-Palindrome if it can be transformed into a palindrome by removing at most k characters from it.
Constraints:
1 <= s.length <= 1000
s has only lowercase English letters.
1 <= k <= s.length
Example:
Input: s = "abcdeca", k = 2 Output: true Explanation: Remove 'b' and 'e' characters.Solution 1: 巧妙地转换成LeetCode 72 Edit Distance 类型的匹配型DP问题
class Solution: def isValidPalindrome(self, s: str, k: int) -> bool: ### convert to Edit Distance Problem ### ==> word1: s, word2: s.reverse(), ### 匹配型DP, f[i][j], s中的前i个, ### 需要remove几次才能匹配s.reverse()的前j个。 ### 这题在决策时不需要考虑replace的情况。 n = len(s) f = [[0] * (n + 1) for _ in range(n + 1)] for i in range(n + 1): for j in range(n + 1): # 初始化 if i == 0: f[0][j] = j continue if j == 0: f[i][0] = i continue # 决策: if s[i - 1] != s[n - j]: f[i][j] = min(f[i - 1][j], f[i][j - 1]) + 1 else: f[i][j] = f[i - 1][j - 1] # 这里注意是两倍的k, # 因为在进行删除操作时, # 例如“abcca“和”accba“ # 进行到在f[2][x]删除一个正序里的"b", # 进行到f[y][4]也会删掉一个倒序的”b“, # 但计算到f[y][4]会把f[2][x]的操作算进去。 # 因为是同一个字符串的相反关系。 # 与edit distance那题不同之处之一在于此。 # 所以每一次删除操作,实际上是被算了两次。 return f[n][n] <= 2 * kSolution 2: 选择使用同LeetCode 680 Valid Palindrome II相似的利用双指针返回index的方法 (recursion) 会超时
class Solution: def isValidPalindrome(self, s: str, k: int) -> bool: return self.isValid(s, 0, len(s) - 1, 0, k) def isValid(self,s, left, right, count, k): left, right = self.find_ptrs(s, left, right) if count > k: return False if left >= right: return True return self.isValid(s, left + 1, right, count + 1, k) or self.isValid(s, left, right - 1, count + 1, k) def find_ptrs(self, s, left, right): while left < right : if s[left] != s[right]: return left, right left += 1 right -= 1 return left, right
-
LeetCode 206 Reverse Linked List
Problem:
Reverse a singly linked list.
Follow up:
A linked list can be reversed either iteratively or recursively. Could you implement both?
Example:
Input: 1->2->3->4->5->NULL Output: 5->4->3->2->1->NULL必须掌握的两种实现方法:
Solution 1: Recursive
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseList(self, head: ListNode) -> ListNode: if head == None or head.next == None: return head p_node = self.reverseList(head.next) head.next.next= head head.next = None return p_nodeSolution 2: Iterative
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseList(self, head: ListNode) -> ListNode: pre = None while head is not None: nextNode = head.next head.next = pre pre = head head = nextNode return pre
-
LeetCode 92 Reverse Linked List II
Problem:
Reverse a linked list from position m to n. Do it in one-pass.
Notes:
1 ≤ m ≤ n ≤ length of list.
Example:
Input: 1->2->3->4->5->NULL, m = 2, n = 4 Output: 1->4->3->2->5->NULLSolution 1: Intuitive Way: Cut , Reverse, Saw (没有One-Pass优化版本)
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode: # method: find mth, nth, and mth_prev, nth_next, cut & saw method # cut into # dummy ->...-> mth_prev # mth_prev -> ... -> nth [Where reverse will happen] # nth_next -> ... -> None # perform reverse, # then saw together dummy = ListNode(-1, head) # starting from dummy to avoid only 1 node list mth_prev, mth, nth, nth_next = self.find_key_nodes(dummy, m + 1, n + 1) # cut mth_prev.next = None nth.next = None # reverse between self.reverse(mth) # saw together mth_prev.next = nth mth.next = nth_next return dummy.next def find_key_nodes(self, head, m, n): count = 0 while head is not None: count += 1 if count == m - 1: mthPrev = head if count == n: nth = head # bacause m <= n: so here we could return return mthPrev, mthPrev.next, nth, nth.next head = head.next return None def reverse(self, head): prev = None while head is not None: nextNode = head.next head.next = prev prev = head head = nextNode return prevSolution 2: One-Pass Iterative 版本:
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode: if m == n: return head dummy = ListNode(0, head) pre = dummy for i in range(m - 1): pre = pre.next # reverse the [m, n] nodes reverse = None cur = pre.next # starts from mth for i in range(n - m + 1): nextNode = cur.next cur.next = reverse reverse = cur cur = nextNode # connect back pre.next.next = cur pre.next = reverse return dummy.next
-
LeetCode 234 Palindrome Linked List
Problem:
Given a singly linked list, determine if it is a palindrome.
Follow up:
Could you do it in O(n) time and O(1) space?
Example:
Input: 1->2 Output: false Input: 1->2->2->1 Output: trueSolution: 快慢指针找到中点,reverse后半段,然后一一比较
这道题需要注意的是如何在链表中用快慢指针找到中点Node并且避免奇偶问题,方法是将middle Node不论奇偶都归在前半段,当作前半段的结尾Node。
O(n) time and O(1) space。
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def isPalindrome(self, head: ListNode) -> bool: if not head: return True middle = self.findMiddle(head) second_half_reversed = self.reverseList(middle.next) if self.checkPalindrome(head, second_half_reversed): return True return False def findMiddle(self, head): slow, fast = head, head while fast.next is not None and fast.next.next is not None: fast = fast.next.next slow = slow.next return slow def reverseList(self, head): prev = None while head is not None: nextNode = head.next head.next = prev prev = head head = nextNode return prev def checkPalindrome(self, head1, head2): while head1 is not None and head2 is not None: if head1.val == head2.val: head1 = head1.next head2 = head2.next continue return False return True
-
Problem:
Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same backward as forward.
Follow up:
Coud you solve it without converting the integer to a string?
Example:
Input: 121 Output: true Input: -121 Output: false Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome. Input: 10 Output: false Explanation: Reads 01 from right to left. Therefore it is not a palindrome.Solution: Mathematic Method
class Solution: def isPalindrome(self, x: int) -> bool: if x < 0: return False origin = x mirror = 0 while x != 0: temp = x % 10 x = int(x / 10) rev = temp mirror = mirror * 10 + rev if origin == mirror: return True return False
-
Problem:
Given a list of unique words, find all pairs of distinct indices (i, j) in the given list, so that the concatenation of the two words, i.e. words[i] + words[j] is a palindrome.
Notes:
Example:
Input: ["abcd","dcba","lls","s","sssll"] Output: [[0,1],[1,0],[3,2],[2,4]] Explanation: The palindromes are ["dcbaabcd","abcddcba","slls","llssssll"] Input: ["bat","tab","cat"] Output: [[0,1],[1,0]] Explanation: The palindromes are ["battab","tabbat"]Solution 1: Hash表 Mapping后用前缀,后缀来解
https://leetcode.com/problems/palindrome-pairs/solution/
class Solution: def palindromePairs(self, words: List[str]) -> List[List[int]]: res = [] table = {} if not words: return res for index, word in enumerate(words): table[word] = index for index, word in enumerate(words): for i in range(len(word) + 1): ### 前缀,后缀 left, right = word[:i], word[i:] if self.isPalindrome(left): reversedRight = right[::-1] if reversedRight in table and table[reversedRight] != index: res.append([table[reversedRight], index]) if len(right) > 0 and self.isPalindrome(right): reversedLeft = left[::-1] if reversedLeft in table and table[reversedLeft] != index: res.append([index, table[reversedLeft]]) return res def isPalindrome(self, s): return s == s[::-1]Solution 2: Trie 利用字典树来解
将所有的单词逆序插入trie树中,然后依次对每个单词进行查询,分为以下两种情况:
1.如果单词的前缀可以在trie树中找到,说明这个单词有可能可以与其组成回文串。然后我们去判断这个单词的剩下的后面部分是否是回文,如果是回文说明确实可以被组成回文串。
比如:查找 "aabc" 的前缀 "aab" 时,发现hash表中有 "aab" ,那么说明 "aabc" 和单词列表中的 "baa" 有可能组成回文串,然后我们判断剩余部分 "c" ,而 "c" 是回文,因此 "aabcbaa" 确实是回文。
2.同理,如果单词的后缀可以在trie树中找到,并且剩余前面部分是回文,那么说明这个单词也可以与其组成回文串。
在这个过程中需注意,单词不能与自身匹配,因此我们把trie树的逆序单词的最后一个字符的index设置为下标。
特殊的,我们会发现,在单词 "abc" 和 "cba" 进行匹配时,对于单词"abc",在 "abc" 作为前缀 且 ""作为剩余后缀时会与 "cba" 匹配一次;对于单词"cba" ,在 "" 作为前缀 且 "cba" 作为后缀时又会与 "abc" 匹配一次。假如 "abc" 和 "cba" 的下标分别是0,1,我们会得到两个[0,1]。因此,我们只要在判断每个字符串时,判断前缀能否找到 或者 后缀能否找到 的时候,只能选其中一种情况考虑为"",就可以排除这种情况。
class TrieNode: def __init__(self): self.next = collections.defaultdict(TrieNode) self.ending_word = -1 self.palindrome_suffixes = [] class Solution: def palindromePairs(self, words): # Create the Trie and add the reverses of all the words. trie = TrieNode() for i, word in enumerate(words): word = word[::-1] # We want to insert the reverse. current_level = trie for j, c in enumerate(word): # Check if remainder of word is a palindrome. if word[j:] == word[j:][::-1]:# Is the word the same as its reverse? current_level.palindrome_suffixes.append(i) # Move down the trie. current_level = current_level.next[c] current_level.ending_word = i # Look up each word in the Trie and find palindrome pairs. solutions = [] for i, word in enumerate(words): current_level = trie for j, c in enumerate(word): # Check for case 3. if current_level.ending_word != -1: if word[j:] == word[j:][::-1]: # Is the word the same as its reverse? solutions.append([i, current_level.ending_word]) if c not in current_level.next: break current_level = current_level.next[c] else: # Case 1 and 2 only come up if whole word was iterated. # Check for case 1. if current_level.ending_word != -1 and current_level.ending_word != i: solutions.append([i, current_level.ending_word]) # Check for case 2. for j in current_level.palindrome_suffixes: solutions.append([i, j]) return solutions
-
LeetCode 833 Find And Replace in String
Problem:
To some string S, we will perform some replacement operations that replace groups of letters with new ones (not necessarily the same size).
Each replacement operation has 3 parameters: a starting index i, a source word x and a target word y. The rule is that if x starts at position i in the original string S, then we will replace that occurrence of x with y. If not, we do nothing.
For example, if we have S = "abcd" and we have some replacement operation i = 2, x = "cd", y = "ffff", then because "cd" starts at position 2 in the original string S, we will replace it with "ffff".
Using another example on S = "abcd", if we have both the replacement operation i = 0, x = "ab", y = "eee", as well as another replacement operation i = 2, x = "ec", y = "ffff", this second operation does nothing because in the original string S[2] = 'c', which doesn't match x[0] = 'e'.
All these operations occur simultaneously. It's guaranteed that there won't be any overlap in replacement: for example, S = "abc", indexes = [0, 1], sources = ["ab","bc"] is not a valid test case.
Notes:
0 <= indexes.length = sources.length = targets.length <= 100
0 < indexes[i] < S.length <= 1000
All characters in given inputs are lowercase letters.
Example:
Input: S = "abcd", indexes = [0,2], sources = ["a","cd"], targets = ["eee","ffff"] Output: "eeebffff" Explanation: "a" starts at index 0 in S, so it's replaced by "eee". "cd" starts at index 2 in S, so it's replaced by "ffff". Input: S = "abcd", indexes = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"] Output: "eeecd" Explanation: "ab" starts at index 0 in S, so it's replaced by "eee". "ec" doesn't starts at index 2 in the original S, so we do nothing.Solution:
class Solution: def findReplaceString(self, S: str, indexes: List[int], sources: List[str], targets: List[str]) -> str: res = '' i = 0 indexes_dict = {} for j, ind in enumerate(indexes): indexes_dict[ind] = j while i < len(S): if i not in indexes_dict.keys(): res += S[i] i += 1 continue source = sources[indexes_dict[i]] if S[i:i + len(source)] == source: res += targets[indexes_dict[i]] i += len(source) else: res += S[i] i += 1 return res
-
Problem:
Given two identical-sized string array A, B and a string S. All substrings A appearing in S are replaced by B.
(Notice: From left to right, it must be replaced if it can be replaced. If there are multiple alternatives, replace longer priorities. After the replacement of the characters can't be replaced again.)
Notes:
The size of each string array does not exceed 100, the total string length does not exceed 50000.
The lengths of A [i] and B [i] are equal.
The length of S does not exceed 50000.
All characters are lowercase letters.
We guarantee that the A array does not have the same string
Example:
Input: A = ["ab","aba"] B = ["cc","ccc"] S = "ababa" Output: "cccba" Explanation: In accordance with the rules, the substring that can be replaced is "ab" or "aba". Since "aba" is longer, we replace "aba" with "ccc". Input: A = ["ab","aba"] B = ["cc","ccc"] S = "aaaaa" Output: "aaaaa" Explanation: S does not contain strings in A, so no replacement is done. Input: A = ["cd","dab","ab"] B = ["cc","aaa","dd"] S = "cdab" Output: "ccdd" Explanation: From left to right, you can find the "cd" can be replaced at first, so after the replacement becomes "ccab", then you can find "ab" can be replaced, so the string after the replacement is "ccdd".Solution: Rolling Hash
这道题在Build最后结果时用的方法,和上一题,LeetCode 833 是一致的,都是从左往右遍历,来build, replace。
这题在寻找相同substring时用到了rolling hash的方法。使得时间复杂度大大降低。
class Solution: """ @param a: The A array @param b: The B array @param s: The S string @return: The answer """ def stringReplace(self, a, b, s): # Write your code here ### rolling hash: BASE = 31 MOD = 100000007 POWER = 1 A_hash = [] for a_string in a: a_hash = 0 for char in a_string: a_hash = (a_hash * BASE + ord(char)) % MOD A_hash.append(a_hash) POWER_list = [1] S_hash = [0] s_hash = 0 for i in s: s_hash = (s_hash * BASE + ord(i)) % MOD S_hash.append(s_hash) POWER = (POWER * BASE) % MOD POWER_list.append(POWER) res = '' i = 0 while i < len(s): max_length = 0 found = -1 for ind, A in enumerate(a): if len(A) + i > len(s): continue S_sub = (S_hash[i + len(A)] - POWER_list[len(A)] * S_hash[i]) % MOD A_sub = A_hash[ind] A_sub = A_sub % MOD S_sub = (S_sub + MOD) % MOD if A_sub == S_sub and max_length < len(A): max_length = len(A) found = ind if found == -1: res += s[i] i += 1 else: res += b[found] i += max_length return res
-
Problem:
Given a paragraph and a list of banned words, return the most frequent word that is not in the list of banned words. It is guaranteed there is at least one word that isn't banned, and that the answer is unique.
Words in the list of banned words are given in lowercase, and free of punctuation. Words in the paragraph are not case sensitive. The answer is in lowercase.
Notes:
1 <= paragraph.length <= 1000.
0 <= banned.length <= 100.
1 <= banned[i].length <= 10.
The answer is unique, and written in lowercase (even if its occurrences in paragraph may have uppercase symbols, and even if it is a proper noun.)
paragraph only consists of letters, spaces, or the punctuation symbols !?',;. There are no hyphens or hyphenated words.
Words only consist of letters, never apostrophes or other punctuation symbols.
Example:
Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." banned = ["hit"] Output: "ball" Explanation: "hit" occurs 3 times, but it is a banned word. "ball" occurs twice (and no other word does), so it is the most frequent non-banned word in the paragraph. Note that words in the paragraph are not case sensitive, that punctuation is ignored (even if adjacent to words, such as "ball,"), and that "hit" isn't the answer even though it occurs more because it is banned.Solution:
class Solution: def mostCommonWord(self, paragraph: str, banned: List[str]) -> str: normalized = '' for char in paragraph: if char.isalnum(): normalized += char.lower() continue normalized += ' ' words = normalized.split() banned = set(banned) most_common = dict() for word in words: if word not in banned: most_common[word] = most_common.get(word, 0) + 1 max_count = max(most_common.values()) # Easy way to write the return the key with max value: return max(most_common, key=most_common.get)
-
LeetCode 937 Reorder Data in Log Files
Problem:
You have an array of logs. Each log is a space delimited string of words.
For each log, the first word in each log is an alphanumeric identifier. Then, either:
Each word after the identifier will consist only of lowercase letters, or; Each word after the identifier will consist only of digits. We will call these two varieties of logs letter-logs and digit-logs. It is guaranteed that each log has at least one word after its identifier.
Reorder the logs so that all of the letter-logs come before any digit-log. The letter-logs are ordered lexicographically ignoring identifier, with the identifier used in case of ties. The digit-logs should be put in their original order.
Return the final order of the logs.
Constraints:
0 <= logs.length <= 100
3 <= logs[i].length <= 100
logs[i] is guaranteed to have an identifier, and a word after the identifier.
Example:
Input: logs = ["dig1 8 1 5 1","let1 art can","dig2 3 6","let2 own kit dig","let3 art zero"] Output: ["let1 art can","let3 art zero","let2 own kit dig","dig1 8 1 5 1","dig2 3 6"]Solution: 在sorted()中用lambda方程和tuples,进行break tie并且符合特定规则的custom排序
class Solution: def reorderLogFiles(self, logs: List[str]) -> List[str]: lets = [] digs = [] for log in logs: if log.split()[1].isdigit(): digs.append(log) else: lets.append(log) # 用lambda方程来些custom sort, # 通过创建(rest,identifier) 这样的tuple来custom比较。 lets = sorted(lets, key=lambda x:(x[x.find(" "):], x[:x.find(" ")])) return lets + digs
-
LeetCode 1268 Search Suggestions System
Problem:
Given an array of strings products and a string searchWord. We want to design a system that suggests at most three product names from products after each character of searchWord is typed. Suggested products should have common prefix with the searchWord. If there are more than three products with a common prefix return the three lexicographically minimums products.
Return list of lists of the suggested products after each character of searchWord is typed.
Constraints:
1 <= products.length <= 1000
There are no repeated elements in products.
1 <= Σ products[i].length <= 2 * 10^4
All characters of products[i] are lower-case English letters.
1 <= searchWord.length <= 1000
All characters of searchWord are lower-case English letters.
Example:
Input: products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse" Output: [ ["mobile","moneypot","monitor"], ["mobile","moneypot","monitor"], ["mouse","mousepad"], ["mouse","mousepad"], ["mouse","mousepad"] ] Explanation: products sorted lexicographically = ["mobile","moneypot","monitor","mouse","mousepad"] After typing m and mo all products match and we show user ["mobile","moneypot","monitor"] After typing mou, mous and mouse the system suggests ["mouse","mousepad"] Input: products = ["havana"], searchWord = "havana" Output: [["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]] Input: products = ["bags","baggage","banner","box","cloths"], searchWord = "bags" Output: [["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]Solution 1: 非常经典的Trie的方法
class TrieNode: def __init__(self): self.children = dict() self.words = [] class Trie: def __init__(self): self.root = TrieNode() def insert(self, word): node = self.root for char in word: if char not in node.children: node.children[char] = TrieNode() node = node.children[char] node.words.append(word) node.words.sort() while len(node.words) > 3: node.words.pop() def search(self, word): res = [] node = self.root for char in word: if char not in node.children: break node = node.children[char] res.append(node.words[:]) l_remain = len(word) - len(res) for _ in range(l_remain): res.append([]) return res class Solution: def suggestedProducts(self, products: List[str], searchWord: str) -> List[List[str]]: trie = Trie() for prod in products: trie.insert(prod) return trie.search(searchWord)Solution 2: Brutal Force with Binary Search
在sorted(products)里,如果 product[i] is product[j]'s prefix, then product[i] is also prefix of product[i + 1], product[i + 2] ... product[j] 。
class Solution: def suggestedProducts(self, products: List[str], searchWord: str) -> List[List[str]]: products.sort() res, prefix, i = [], '', 0 for c in searchWord: prefix += c i = bisect.bisect_left(products, prefix, i) res.append([w for w in products[i:i + 3] if w.startswith(prefix)]) return res
-
LeetCode 97. Interleaving String
Problem:
Given s1, s2, s3, find whether s3 is formed by the interleaving of s1 and s2.
Example:
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac" Output: true Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc" Output: falseSolution:
DP:
class Solution: def isInterleave(self, s1: str, s2: str, s3: str) -> bool: m = len(s1) n = len(s2) k = len(s3) if m + n != k: return False if m == 0 or n == 0: if s1 == s3 or s2 == s3: return True else: return False f = [[False] * (n + 1) for _ in range(m + 1)] f[0][0] = True # f[i][j] represents s1[0...i-1] and s2[0...j-1] interleave to form s3[0...(i + j - 1)] # thus, check if s3[i + j - 1] is either from s1[i-1] or s2[j-1], then f[i-1][j] or f[i][j-1] must be true accordingly for i in range(m + 1): for j in range( n + 1): if i + j - 1 >= 0: f[i][j] = (f[i - 1][j] and s3[i + j - 1] == s1[i - 1]) or (s3[i + j - 1] == s2[j - 1] and f[i][j - 1]) return f[m][n]
-
LeetCode 14 Longest Common Prefix
Problem:
Write a function to find the longest common prefix string amongst an array of strings.
If there is no common prefix, return an empty string "".
Notes:
All given inputs are in lowercase letters a-z.
Example:
Example 1: Input: ["flower","flow","flight"] Output: "fl" Example 2: Input: ["dog","racecar","car"] Output: "" Explanation: There is no common prefix among the input strings.Solution: Trie的经典应用
Trie, 重点在于search LCP的return 条件是,字典树向下走时最先出现词尾或者最先出现分叉的时候。
class TrieNode: def __init__(self): self.children = {} self.end = False class Trie: def __init__(self): self.root = TrieNode() def add(self, word): if not word: return node = self.root for char in word: # if not in the children if char not in node.children: node.children[char] = TrieNode() node = node.children[char] # mark when at the end of the word: node.end = True return class Solution: def longestCommonPrefix(self, strs: List[str]) -> str: if not strs: return "" trie = Trie() for str in strs: # avoid empty str in strs if str == "": return "" trie.add(str) lcp = self.searchLCP(trie.root) return lcp def searchLCP(self, node): res = '' while node: # the LCP happens either at the first word end, or the first ramification happens # 所以这里可以return结果 if node.end or len(node.children) > 1: return res char = list(node.children)[0] res += char node = node.children[char] return res
-
Problem:
Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
An input string is valid if:
Open brackets must be closed by the same type of brackets.
Open brackets must be closed in the correct order.
Note that an empty string is also considered valid.
Example:
Input: "()" Output: true Input: "()[]{}" Output: true Input: "(]" Output: false Input: "([)]" Output: false Input: "{[]}" Output: trueSolution: 用哈希表作 map,用Stack来解的方法
https://leetcode.com/problems/valid-parentheses/solution/
class Solution: def isValid(self, s: str) -> bool: stack = [] map = { "]":"[", "}":"{", ")":"(" } for p in s: # if p is left parentheses, put it in the stack if p in map.values(): stack.append(p) # if p is right paretheses, # check if stack has anything, and pop the top element and check if matches, # Otherwise return False elif p in map: if stack and stack.pop() == map[p]: continue return False # Finally check if stack is empty return stack == []
-
LeetCode 22 Generate Parentheses
Problem:
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
Example:
For example, given n = 3, a solution set is: [ "((()))", "(()())", "(())()", "()(())", "()()()" ]Solution: backtracking
class Solution: def generateParenthesis(self, n: int) -> List[str]: res = [] self.backtrack('', 0, 0, n, res) return res def backtrack(self, s, left, right, N, res): if len(s) == 2 * N: res.append(s) return if left < N: self.backtrack(s + '(', left + 1, right, N, res) if right < left: self.backtrack(s + ')', left, right + 1, N, res)
-
Problem:
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000 For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9. X can be placed before L (50) and C (100) to make 40 and 90. C can be placed before D (500) and M (1000) to make 400 and 900. Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range from 1 to 3999.
Example:
Input: 3 Output: "III" Input: 4 Output: "IV" Input: 9 Output: "IX" Input: 58 Output: "LVIII" Explanation: L = 50, V = 5, III = 3. Input: 1994 Output: "MCMXCIV" Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.Solution: Greedy, 从大的位数开始到小的位数
digits = [(1000, "M"), (900, "CM"), (500, "D"), (400, "CD"), (100, "C"), (90, "XC"), (50, "L"), (40, "XL"), (10, "X"), (9, "IX"), (5, "V"), (4, "IV"), (1, "I")] class Solution: def intToRoman(self, num: int) -> str: roman_digits = [] # Loop through each symbol. for value, symbol in digits: # We don't want to continue looping if we're done. if num == 0: break count, num = divmod(num, value) # Append "count" copies of "symbol" to roman_digits. roman_digits.append(symbol * count) return "".join(roman_digits)
-
Problem:
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000 For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9. X can be placed before L (50) and C (100) to make 40 and 90. C can be placed before D (500) and M (1000) to make 400 and 900. Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999.
Example:
Input: "III" Output: 3 Input: "IV" Output: 4 Input: "IX" Output: 9 Input: "LVIII" Output: 58 Explanation: L = 50, V= 5, III = 3. Input: "MCMXCIV" Output: 1994 Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.Solution 1:
values = { "I": 1, "V": 5, "X": 10, "L": 50, "C": 100, "D": 500, "M": 1000, "IV": 4, "IX": 9, "XL": 40, "XC": 90, "CD": 400, "CM": 900 } class Solution: def romanToInt(self, s: str) -> int: n = len(s) ptr = 0 out = 0 while ptr < n: i = n - ptr- 1 if s[i-1:i+1] in values: out += values[s[i-1:i+1]] ptr += 2 elif s[i] in values: out += values[s[i]] ptr += 1 return outSolution 2:
values = { "I": 1, "V": 5, "X": 10, "L": 50, "C": 100, "D": 500, "M": 1000, } class Solution: def romanToInt(self, s: str) -> int: total = values.get(s[-1]) for i in reversed(range(len(s) - 1)): if values[s[i]] < values[s[i + 1]]: total -= values[s[i]] else: total += values[s[i]] return totalSolution 3:
d = {'M':1000, 'D':500, 'C':100, 'L':50, 'X':10, 'V':5, 'I':1} class Solution: def romanToInt(self, s: str) -> int: res, p = 0, 'I' for c in s[::-1]: res, p = res - d[c] if d[c] < d[p] else res + d[c], c return res
-
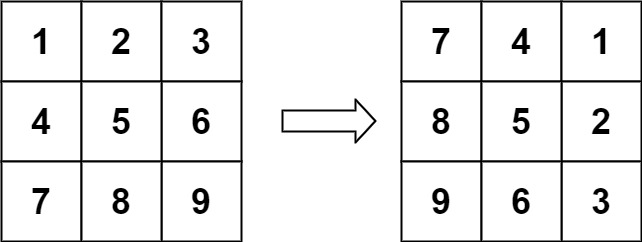
Problem:
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Constraints:
matrix.length == n
matrix[i].length == n
1 <= n <= 20
-1000 <= matrix[i][j] <= 1000
Example:
Input: matrix = [[1,2,3],[4,5,6],[7,8,9]] Output: [[7,4,1],[8,5,2],[9,6,3]] Input: matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]] Output: [[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] Input: matrix = [[1]] Output: [[1]] Input: matrix = [[1,2],[3,4]] Output: [[3,1],[4,2]]Solution: 先transpose, 再每行reverse,这样就等于旋转了90度。注意transpose的方法,这里因为是nxn,所以简化了。
class Solution: def rotate(self, matrix: List[List[int]]) -> None: """ Do not return anything, modify matrix in-place instead. """ """ :type matrix: List[List[int]] :rtype: void Do not return anything, modify matrix in-place instead. """ n = len(matrix[0]) # transpose matrix for i in range(n): for j in range(i, n): matrix[j][i], matrix[i][j] = matrix[i][j], matrix[j][i] # reverse each row for i in range(n): matrix[i].reverse()
补充类似题目 Rotate And Fall 游戏:
You are given a matrix of characters representing a big box. Each cell of the matrix contains one of three characters:
'.', which means that the cell is empty
'*', which means that the cell contains an obstacle
'#', which means that the cell contains a small box
You decide to rotate the big box clockwise to see how the small boxes will fall under the gravity. After rotating, each small box falls down until it lands on an obstacle, another small box, or the bottom of the big box.
Given box, a matrix representation of the big box, your task is to return the state of the box after rotating it clockwise.
Example:
box = [
['#', '#', '.', '.', '.', '.', '.'],
['#', '#', '#', '.', '.', '.', '.'],
['#', '#', '#', '.', '.', '#', '.']
]
rotateAndFall(box) = [
['.', '.', '.'],
['.', '.', '.'],
['.', '.', '.'],
['#', '.', '.'],
['#', '#', '.'],
['#', '#', '#'],
['#', '#', '#'],
]
Solution:
def rotateAndFall(box):
for row in box:
fallByRow(row)
res = rotate(box)
return res
def fallByRow(row):
fast, slow = len(row) - 1, len(row) - 1
# slow is pointing to where could be filled by fall
while fast >= 0:
if row[fast] == '#':
# swap
row[fast], row[slow] = row[slow], row[fast]
slow -= 1
elif row[fast] == '*':
slow = fast - 1
else:
pass
fast -= 1
return
def rotate(matrix):
m , n = len(matrix), len(matrix[0])
# transpose:
transposed = [[matrix[j][i] for j in range(m)] for i in range(n)]
# reverse by new row
for i in range(n):
transposed[i].reverse()
return transposed
box = [
['#', '#', '.', '.', '.', '.', '.'],
['#', '#', '#', '.', '.', '.', '.'],
['#', '#', '#', '.', '.', '#', '.']
]
print(rotateAndFall(box))
-
Problem:
Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find the one that is missing from the array.
Notes:
Your algorithm should run in linear runtime complexity. Could you implement it using only constant extra space complexity?
Example:
Input: [3,0,1] Output: 2 Input: [9,6,4,2,3,5,7,0,1] Output: 8Solution:
class Solution: def missingNumber(self, nums: List[int]) -> int: num_set = set(nums) n = len(nums) + 1 for number in range(n): if number not in num_set: return number
-
LeetCode 41 First Missing Positive
Problem:
Given an unsorted integer array, find the smallest missing positive integer.
Notes:
Your algorithm should run in O(n) time and uses constant extra space.
Example:
Input: [1,2,0] Output: 3 Input: [3,4,-1,1] Output: 2 Input: [7,8,9,11,12] Output: 1Solution: 利用bucket sort的思想来解,注意条件比较复杂
比如:
index = [0, 1, 2, 3]
nums = [1, 4, -1, 2]
应该按index来说,index对应的数是index + 1, 按这个规律不完全排序一遍。(并不是真的排序,只是把符合条件的放回符合条件的地方)
nums_sorted = [1, 2, -1, 4]
那么再进行第二次遍历,第一个不符合条件的就是first missing positive。
class Solution: def firstMissingPositive(self, nums: List[int]) -> int: # bucket sort idea: if not nums or len(nums) == 0: return 1 # 先in-place 把出现的正数num发放进应该的index for i in range(len(nums)): while nums[i] > 0 and nums[i] <= len(nums) and nums[nums[i] - 1] != nums[i]: nums[nums[i] - 1], nums[i] = nums[i], nums[nums[i] - 1] # 找出当前index对应错误的数,那么就找到了missing value for i in range(len(nums)): if nums[i] != i + 1: return i + 1 # 最后一定要再防止本来nums就全满足条件,比如[1, 2, 3, 4]这种,return的应该是5。 return len(nums) + 1
-
LeetCode 581 Shortest Unsorted Continuous Subarray
Problem:
Given an integer array, you need to find one continuous subarray that if you only sort this subarray in ascending order, then the whole array will be sorted in ascending order, too.
You need to find the shortest such subarray and output its length.
Notes:
Then length of the input array is in range [1, 10,000].
The input array may contain duplicates, so ascending order here means <=.
Example:
Input: [2, 6, 4, 8, 10, 9, 15] Output: 5 Explanation: You need to sort [6, 4, 8, 10, 9] in ascending order to make the whole array sorted in ascending order.Solution:
class Solution: def findUnsortedSubarray(self, nums: List[int]) -> int: # 初步search # [0...start] sorted, # [end....n-1] sorted # [start + 1, .... end - 1] unsorted, # 第二步 filter # we need to make sure [0....start]'s max is less than min of unsorted # and [end ... n - 1]'s min is larger than max of unsorted if not nums or len(nums) <= 1: return 0 # 初步search start, end = 0, len(nums) - 1 while start + 1 <= len(nums) - 1 and nums[start] <= nums[start + 1]: start += 1 while end - 1 >= 0 and nums[end] >= nums[end - 1]: end -= 1 # 此处可以进行判断,如果start位置在end的右侧,说明不需要排序。 if start > end: return 0 # 找到unsorted subarray的min和max cur_min, cur_max = self.findLocalMaxMin(nums, start, end) # 开始filter sorted 的部分 while start > 0 and cur_min < nums[start-1]: start -= 1 while end < len(nums) - 1 and cur_max > nums[end + 1]: end += 1 return end - start + 1 def findLocalMaxMin(self, nums, start, end): minVal = float('inf') maxVal = float('-inf') for i in range(start, end + 1): minVal = min(minVal, nums[i]) maxVal = max(maxVal, nums[i]) return minVal, maxVal
-
LeetCode 325 Maximum Size Subarray Sum Equals k
Problem:
Given an array nums and a target value k, find the maximum length of a subarray that sums to k. If there isn't one, return 0 instead.
Notes:
The sum of the entire nums array is guaranteed to fit within the 32-bit signed integer range.
Example:
Input: nums = [1, -1, 5, -2, 3], k = 3 Output: 4 Explanation: The subarray [1, -1, 5, -2] sums to 3 and is the longest. Input: nums = [-2, -1, 2, 1], k = 1 Output: 2 Explanation: The subarray [-1, 2] sums to 1 and is the longest.Solution: Two SUM 类型的题目,先构造PrefixSUM, 然后进行Two SUM, 打擂台
构造prefixSUM 的同时,完成Two SUM 找curr - k 的操作,同时用Hash记录的时候,记得去重,只能计入当Key的prefixSUM相同时最左边的index。
class Solution: def maxSubArrayLen(self, nums: List[int], k: int) -> int: if not nums: return 0 # 这题的本质是two sum问题 # 先建立一个prefixSUM # 然后对prefixSUM进行two sum 找 curr-k # 注意边界条件 Hash = {} prefixSUM = [0] * (len(nums) + 1) maxLen = float('-inf') for i in range(len(prefixSUM)): if i - 1 >= 0: prefixSUM[i] = prefixSUM[i - 1] + nums[i - 1] diff = prefixSUM[i] - k if diff in Hash and Hash[diff] <= i: maxLen = max(maxLen, i - Hash[diff]) if prefixSUM[i] not in Hash: Hash[prefixSUM[i]] = i if maxLen == float('-inf'): return 0 return maxLen